
Abstract
In recent years the interest in obfuscation has increased, mainly because people want to protect their intellectual property. Unfortunately, most of what’s been written is focused on the theoretical aspects. In this article, we will discuss the practical engineering challenges of developing a low-footprint virtual machine interpreter. The VM is easily embeddable, built on open-source technology and has various hardening features that were achieved with minimal effort.
Introduction
In addition to protecting intellectual property, a minimal virtual machine can be useful for other reasons. You might want to have an embeddable interpreter to execute business logic (shellcode), without having to deal with RWX memory. It can also be useful as an educational tool, or just for fun.
Creating a custom VM architecture (similar to VMProtect/Themida) means that we would have to deal with binary rewriting/lifting or write our own compiler. Instead, we decided to use a preexisting architecture, which would be supported by LLVM: RISC-V. This architecture is already widely used for educational purposes and has the advantage of being very simple to understand and implement.
Initially, the main contender was WebAssembly. However, existing interpreters were very bloated and would also require dealing with a binary format. Additionally, it looks like WASM64 is very underdeveloped and our memory model requires 64-bit pointer support. SPARC and PowerPC were also considered, but RISC-V seems to be more popular and there are a lot more resources available for it.
WebAssembly was designed for sandboxing and therefore strictly separates guest and host memory. Because we will be writing our own RISC-V interpreter, we chose to instead share memory between the guest and the host. This means that pointers in the RISC-V execution context (the guest) are valid in the host process and vice-versa.
As a result, the instructions responsible for reading/writing memory can be implemented as a simple memcpy call and we do not need additional code to translate/validate memory accesses (which helps with our goal of small code size). With this property, we need to implement only two system calls to perform arbitrary operations in the host process:
uintptr_t riscvm_get_peb();
uintptr_t riscvm_host_call(uintptr_t rip, uintptr_t args[13]);
The riscvm_get_peb is Windows-specific and it allows us to resolve exports, which we can then pass to the riscvm_host_call function to execute arbitrary code. Additionally, an optional host_syscall stub could be implemented, but this is not strictly necessary since we can just call the functions in ntdll.dll instead.
Toolchain and CRT
To keep the interpreter footprint as low as possible, we decided to develop a toolchain that outputs a freestanding binary. The goal is to copy this binary into memory and point the VM’s program counter there to start execution. Because we are in freestanding mode, there is no C runtime available to us, this requires us to handle initialization ourselves.
As an example, we will use the following hello.c file:
int _start() {
int result = 0;
for(int i = 0; i < 52; i++) {
result += *(volatile int*)&i;
}
return result + 11;
}
We compile the program with the following incantation:
clang -target riscv64 -march=rv64im -mcmodel=medany -Os -c hello.c -o hello.o
And then verify by disassembling the object:
$ llvm-objdump --disassemble hello.o
hello.o: file format elf64-littleriscv
0000000000000000 <_start>:
0: 13 01 01 ff addi sp, sp, -16
4: 13 05 00 00 li a0, 0
8: 23 26 01 00 sw zero, 12(sp)
c: 93 05 30 03 li a1, 51
0000000000000010 <.LBB0_1>:
10: 03 26 c1 00 lw a2, 12(sp)
14: 33 05 a6 00 add a0, a2, a0
18: 9b 06 16 00 addiw a3, a2, 1
1c: 23 26 d1 00 sw a3, 12(sp)
20: 63 40 b6 00 blt a2, a1, 0x20 <.LBB0_1+0x10>
24: 1b 05 b5 00 addiw a0, a0, 11
28: 13 01 01 01 addi sp, sp, 16
2c: 67 80 00 00 ret
The hello.o is a regular ELF object file. To get a freestanding binary we need to invoke the linker with a linker script:
ENTRY(_start)
LINK_BASE = 0x8000000;
SECTIONS
{
. = LINK_BASE;
__base = .;
.text : ALIGN(16) {
. = LINK_BASE;
*(.text)
*(.text.*)
}
.data : {
*(.rodata)
*(.rodata.*)
*(.data)
*(.data.*)
*(.eh_frame)
}
.init : {
__init_array_start = .;
*(.init_array)
__init_array_end = .;
}
.bss : {
*(.bss)
*(.bss.*)
*(.sbss)
*(.sbss.*)
}
.relocs : {
. = . + SIZEOF(.bss);
__relocs_start = .;
}
}
This script is the result of an excessive amount of swearing and experimentation. The format is .name : { ... } where .name is the destination section and the stuff in the brackets is the content to paste in there. The special . operator is used to refer to the current position in the binary and we define a few special symbols for use by the runtime:
| Symbol | Meaning |
|---|---|
__base | Base of the executable. |
__init_array_start | Start of the C++ init arrays. |
__init_array_end | End of the C++ init arrays. |
__relocs_start | Start of the relocations (end of the binary). |
These symbols are declared as extern in the C code and they will be resolved at link-time. While it may seem confusing at first that we have a destination section, it starts to make sense once you realize the linker has to output a regular ELF executable. That ELF executable is then passed to llvm-objcopy to create the freestanding binary blob. This makes debugging a whole lot easier (because we get DWARF symbols) and since we will not implement an ELF loader, it also allows us to extract the relocations for embedding into the final binary.
To link the intermediate ELF executable and then create the freestanding hello.pre.bin:
ld.lld.exe -o hello.elf --oformat=elf -emit-relocs -T ..\lib\linker.ld --Map=hello.map hello.o
llvm-objcopy -O binary hello.elf hello.pre.bin
For debugging purposes we also output hello.map, which tells us exactly where the linker put the code/data:
VMA LMA Size Align Out In Symbol
0 0 0 1 LINK_BASE = 0x8000000
0 0 8000000 1 . = LINK_BASE
8000000 0 0 1 __base = .
8000000 8000000 30 16 .text
8000000 8000000 0 1 . = LINK_BASE
8000000 8000000 30 4 hello.o:(.text)
8000000 8000000 30 1 _start
8000010 8000010 0 1 .LBB0_1
8000030 8000030 0 1 .init
8000030 8000030 0 1 __init_array_start = .
8000030 8000030 0 1 __init_array_end = .
8000030 8000030 0 1 .relocs
8000030 8000030 0 1 . = . + SIZEOF ( .bss )
8000030 8000030 0 1 __relocs_start = .
0 0 18 8 .rela.text
0 0 18 8 hello.o:(.rela.text)
0 0 3b 1 .comment
0 0 3b 1 <internal>:(.comment)
0 0 30 1 .riscv.attributes
0 0 30 1 <internal>:(.riscv.attributes)
0 0 108 8 .symtab
0 0 108 8 <internal>:(.symtab)
0 0 55 1 .shstrtab
0 0 55 1 <internal>:(.shstrtab)
0 0 5c 1 .strtab
0 0 5c 1 <internal>:(.strtab)
The final ingredient of the toolchain is a small Python script (relocs.py) that extracts the relocations from the ELF file and appends them to the end of the hello.pre.bin. The custom relocation format only supports R_RISCV_64 and is resolved by our CRT like so:
typedef struct
{
uint8_t type;
uint32_t offset;
int64_t addend;
} __attribute__((packed)) Relocation;
extern uint8_t __base[];
extern uint8_t __relocs_start[];
#define LINK_BASE 0x8000000
#define R_RISCV_NONE 0
#define R_RISCV_64 2
static __attribute((noinline)) void riscvm_relocs()
{
if (*(uint32_t*)__relocs_start != 'ALER')
{
asm volatile("ebreak");
}
uintptr_t load_base = (uintptr_t)__base;
for (Relocation* itr = (Relocation*)(__relocs_start + sizeof(uint32_t)); itr->type != R_RISCV_NONE; itr++)
{
if (itr->type == R_RISCV_64)
{
uint64_t* ptr = (uint64_t*)((uintptr_t)itr->offset - LINK_BASE + load_base);
*ptr -= LINK_BASE;
*ptr += load_base;
}
else
{
asm volatile("ebreak");
}
}
}
As you can see, the __base and __relocs_start magic symbols are used here. The only reason this works is the -mcmodel=medany we used when compiling the object. You can find more details in this article and in the RISC-V ELF Specification. In short, this flag allows the compiler to assume that all code will be emitted in a 2 GiB address range, which allows more liberal PC-relative addressing. The R_RISCV_64 relocation type gets emitted when you put pointers in the .data section:
void* functions[] = {
&function1,
&function2,
};
This also happens when using vtables in C++, and we wanted to support these properly early on, instead of having to fight with horrifying bugs later.
The next piece of the CRT involves the handling of the init arrays (which get emitted by global instances of classes that have a constructor):
typedef void (*InitFunction)();
extern InitFunction __init_array_start;
extern InitFunction __init_array_end;
static __attribute((optnone)) void riscvm_init_arrays()
{
for (InitFunction* itr = &__init_array_start; itr != &__init_array_end; itr++)
{
(*itr)();
}
}
Frustratingly, we were not able to get this function to generate correct code without the __attribute__((optnone)). We suspect this has to do with aliasing assumptions (the start/end can technically refer to the same memory), but we didn’t investigate this further.
Interpreter internals
Note: the interpreter was initially based on riscvm.c by edubart. However, we have since completely rewritten it in C++ to better suit our purpose.
Based on the RISC-V Calling Conventions document, we can create an enum for the 32 registers:
enum RegIndex
{
reg_zero, // always zero (immutable)
reg_ra, // return address
reg_sp, // stack pointer
reg_gp, // global pointer
reg_tp, // thread pointer
reg_t0, // temporary
reg_t1,
reg_t2,
reg_s0, // callee-saved
reg_s1,
reg_a0, // arguments
reg_a1,
reg_a2,
reg_a3,
reg_a4,
reg_a5,
reg_a6,
reg_a7,
reg_s2, // callee-saved
reg_s3,
reg_s4,
reg_s5,
reg_s6,
reg_s7,
reg_s8,
reg_s9,
reg_s10,
reg_s11,
reg_t3, // temporary
reg_t4,
reg_t5,
reg_t6,
};
We just need to add a pc register and we have the structure to represent the RISC-V CPU state:
struct riscvm
{
int64_t pc;
uint64_t regs[32];
};
It is important to keep in mind that the zero register is always set to 0 and we have to prevent writes to it by using a macro:
#define reg_write(idx, value) \
do \
{ \
if (LIKELY(idx != reg_zero)) \
{ \
self->regs[idx] = value; \
} \
} while (0)
The instructions (ignoring the optional compression extension) are always 32-bits in length and can be cleanly expressed as a union:
union Instruction
{
struct
{
uint32_t compressed_flags : 2;
uint32_t opcode : 5;
uint32_t : 25;
};
struct
{
uint32_t opcode : 7;
uint32_t rd : 5;
uint32_t funct3 : 3;
uint32_t rs1 : 5;
uint32_t rs2 : 5;
uint32_t funct7 : 7;
} rtype;
struct
{
uint32_t opcode : 7;
uint32_t rd : 5;
uint32_t funct3 : 3;
uint32_t rs1 : 5;
uint32_t rs2 : 5;
uint32_t shamt : 1;
uint32_t imm : 6;
} rwtype;
struct
{
uint32_t opcode : 7;
uint32_t rd : 5;
uint32_t funct3 : 3;
uint32_t rs1 : 5;
uint32_t imm : 12;
} itype;
struct
{
uint32_t opcode : 7;
uint32_t rd : 5;
uint32_t imm : 20;
} utype;
struct
{
uint32_t opcode : 7;
uint32_t rd : 5;
uint32_t imm12 : 8;
uint32_t imm11 : 1;
uint32_t imm1 : 10;
uint32_t imm20 : 1;
} ujtype;
struct
{
uint32_t opcode : 7;
uint32_t imm5 : 5;
uint32_t funct3 : 3;
uint32_t rs1 : 5;
uint32_t rs2 : 5;
uint32_t imm7 : 7;
} stype;
struct
{
uint32_t opcode : 7;
uint32_t imm_11 : 1;
uint32_t imm_1_4 : 4;
uint32_t funct3 : 3;
uint32_t rs1 : 5;
uint32_t rs2 : 5;
uint32_t imm_5_10 : 6;
uint32_t imm_12 : 1;
} sbtype;
int16_t chunks16[2];
uint32_t bits;
};
static_assert(sizeof(Instruction) == sizeof(uint32_t), "");
There are 13 top-level opcodes (Instruction.opcode) and some of those opcodes have another field that further specializes the functionality (i.e. Instruction.itype.funct3). To keep the code readable, the enumerations for the opcode are defined in opcodes.h. The interpreter is structured to have handler functions for the top-level opcode in the following form:
bool handler_rv64_<opcode>(riscvm_ptr self, Instruction inst);
As an example, we can look at the handler for the lui instruction (note that the handlers themselves are responsible for updating pc):
ALWAYS_INLINE static bool handler_rv64_lui(riscvm_ptr self, Instruction inst)
{
int64_t imm = bit_signer(inst.utype.imm, 20) << 12;
reg_write(inst.utype.rd, imm);
self->pc += 4;
dispatch(); // return true;
}
The interpreter executes until one of the handlers returns false, indicating the CPU has to halt:
void riscvm_run(riscvm_ptr self)
{
while (true)
{
Instruction inst;
inst.bits = *(uint32_t*)self->pc;
if (!riscvm_execute_handler(self, inst))
break;
}
}
Plenty of articles have been written about the semantics of RISC-V, so you can look at the source code if you’re interested in the implementation details of individual instructions. The structure of the interpreter also allows us to easily implement obfuscation features, which we will discuss in the next section.
For now, we will declare the handler functions as __attribute__((always_inline)) and set the -fno-jump-tables compiler option, which gives us a riscvm_run function that (comfortably) fits into a single page (0xCA4 bytes):
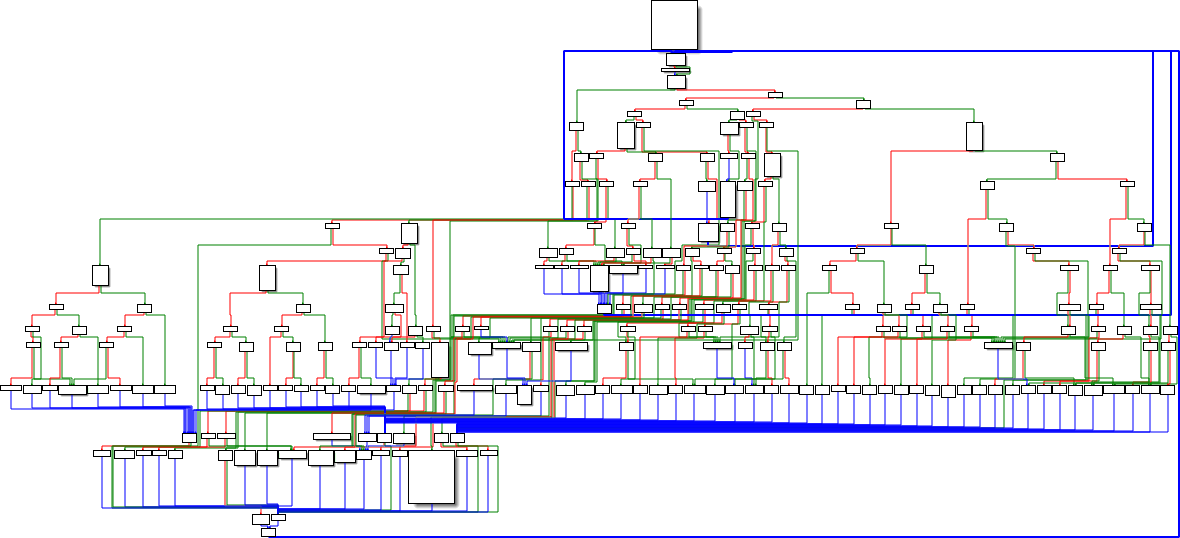
Hardening features
A regular RISC-V interpreter is fun, but an attacker can easily reverse engineer our payload by throwing it into Ghidra to decompile it. To force the attacker to at least look at our VM interpreter, we implemented a few security features. These features are implemented in a Python script that parses the linker MAP file and directly modifies the opcodes: encrypt.py.
Opcode shuffling
The most elegant (and likely most effective) obfuscation is to simply reorder the enums of the instruction opcodes and sub-functions. The shuffle.py script is used to generate shuffled_opcodes.h, which is then included into riscvm.h instead of opcodes.h to mix the opcodes:
#ifdef OPCODE_SHUFFLING
#warning Opcode shuffling enabled
#include "shuffled_opcodes.h"
#else
#include "opcodes.h"
#endif // OPCODE_SHUFFLING
There is also a shuffled_opcodes.json file generated, which is parsed by encrypt.py to know how to shuffle the assembled instructions.
Because enums are used for all the opcodes, we only need to recompile the interpreter to obfuscate it; there is no additional complexity cost in the implementation.
Bytecode encryption
To increase diversity between payloads for the same VM instance, we also employ a simple ‘encryption’ scheme on top of the opcode:
ALWAYS_INLINE static uint32_t tetra_twist(uint32_t input)
{
/**
* Custom hash function that is used to generate the encryption key.
* This has strong avalanche properties and is used to ensure that
* small changes in the input result in large changes in the output.
*/
constexpr uint32_t prime1 = 0x9E3779B1; // a large prime number
input ^= input >> 15;
input *= prime1;
input ^= input >> 12;
input *= prime1;
input ^= input >> 4;
input *= prime1;
input ^= input >> 16;
return input;
}
ALWAYS_INLINE static uint32_t transform(uintptr_t offset, uint32_t key)
{
uint32_t key2 = key + offset;
return tetra_twist(key2);
}
ALWAYS_INLINE static uint32_t riscvm_fetch(riscvm_ptr self)
{
uint32_t data;
memcpy(&data, (const void*)self->pc, sizeof(data));
#ifdef CODE_ENCRYPTION
return data ^ transform(self->pc - self->base, self->key);
#else
return data;
#endif // CODE_ENCRYPTION
}
The offset relative to the start of the bytecode is used as the seed to a simple transform function. The result of this function is XOR’d with the instruction data before decoding. The exact transformation doesn’t really matter, because an attacker can always observe the decrypted bytecode at runtime. However, static analysis becomes more difficult and pattern-matching the payload is prevented, all for a relatively small increase in VM implementation complexity.
It would be possible to encrypt the contents of the .data section of the payload as well, but we would have to completely decrypt it in memory before starting execution anyway. Technically, it would be also possible to implement a lazy encryption scheme by customizing the riscvm_read and riscvm_write functions to intercept reads/writes to the payload region, but this idea was not pursued further.
Threaded handlers
The most interesting feature of our VM is that we only need to make minor code modifications to turn it into a so-called threaded interpreter. Threaded code is a well-known technique used both to speed up emulators and to introduce indirect branches that complicate reverse engineering. It is called threading because the execution can be visualized as a thread of handlers that directly branch to the next handler. There is no classical dispatch function, with an infinite loop and a switch case for each opcode inside. The performance improves because there are fewer false-positives in the branch predictor when executing threaded code. You can find more information about threaded interpreters in the Dispatch Techniques section of the YETI paper.
The first step is to construct a handler table, where each handler is placed at the index corresponding to each opcode. To do this we use a small snippet of constexpr C++ code:
typedef bool (*riscvm_handler_t)(riscvm_ptr, Instruction);
static constexpr std::array<riscvm_handler_t, 32> riscvm_handlers = []
{
// Pre-populate the table with invalid handlers
std::array<riscvm_handler_t, 32> result = {};
for (size_t i = 0; i < result.size(); i++)
{
result[i] = handler_rv64_invalid;
}
// Insert the opcode handlers at the right index
#define INSERT(op) result[op] = HANDLER(op)
INSERT(rv64_load);
INSERT(rv64_fence);
INSERT(rv64_imm64);
INSERT(rv64_auipc);
INSERT(rv64_imm32);
INSERT(rv64_store);
INSERT(rv64_op64);
INSERT(rv64_lui);
INSERT(rv64_op32);
INSERT(rv64_branch);
INSERT(rv64_jalr);
INSERT(rv64_jal);
INSERT(rv64_system);
#undef INSERT
return result;
}();
With the riscvm_handlers table populated we can define the dispatch macro:
#define dispatch() \
Instruction next; \
next.bits = riscvm_fetch(self); \
if (next.compressed_flags != 0b11) \
{ \
panic("compressed instructions not supported!"); \
} \
__attribute__((musttail)) return riscvm_handlers[next.opcode](self, next)
The musttail attribute forces the call to the next handler to be a tail call. This is only possible because all the handlers have the same function signature and it generates an indirect branch to the next handler:
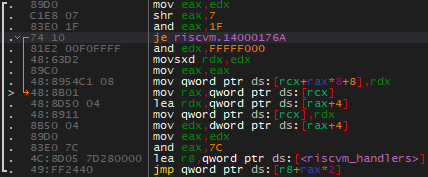
The final piece of the puzzle is the new implementation of the riscvm_run function, which uses an empty riscvm_execute handler to bootstrap the chain of execution:
ALWAYS_INLINE static bool riscvm_execute(riscvm_ptr self, Instruction inst)
{
dispatch();
}
NEVER_INLINE void riscvm_run(riscvm_ptr self)
{
Instruction inst;
riscvm_execute(self, inst);
}
Traditional obfuscation
The built-in hardening features that we can get with a few #ifdefs and a small Python script are good enough for a proof-of-concept, but they are not going to deter a determined attacker for a very long time. An attacker can pattern-match the VM’s handlers to simplify future reverse engineering efforts. To address this, we can employ common obfuscation techniques using LLVM obfuscation passes:
- Instruction substitution (to make pattern matching more difficult)
- Opaque predicates (to hinder static analysis)
- Inject anti-debug checks (to make dynamic analysis more difficult)
The paper Modern obfuscation techniques by Roman Oravec gives a nice overview of literature and has good data on what obfuscation passes are most effective considering their runtime overhead.
Additionally, it would also be possible to further enhance the VM’s security by duplicating handlers, but this would require extra post-processing on the payload itself. The VM itself is only part of what could be obfuscated. Obfuscating the payloads themselves is also something we can do quite easily. Most likely, manually-integrated security features (stack strings with xorstr, lazy_importer and variable encryption) will be most valuable here. However, because we use LLVM to build the payloads we can also employ automated obfuscation there. It is important to keep in mind that any overhead created in the payloads themselves is multiplied by the overhead created by the handler obfuscation, so experimentation is required to find the sweet spot for your use case.
Writing the payloads
The VM described in this post so far technically has the ability to execute arbitrary code. That being said, it would be rather annoying for an end-user to write said code. For example, we would have to manually resolve all imports and then use the riscvm_host_call function to actually execute them. These functions are executing in the RISC-V context and their implementation looks like this:
uintptr_t riscvm_host_call(uintptr_t address, uintptr_t args[13])
{
register uintptr_t a0 asm("a0") = address;
register uintptr_t a1 asm("a1") = (uintptr_t)args;
register uintptr_t a7 asm("a7") = 20000;
asm volatile("scall" : "+r"(a0) : "r"(a1), "r"(a7));
return a0;
}
uintptr_t riscvm_get_peb()
{
register uintptr_t a0 asm("a0") = 0;
register uintptr_t a7 asm("a7") = 20001;
asm volatile("scall" : "+r"(a0) : "r"(a7) : "memory");
return a0;
}
We can get a pointer to the PEB using riscvm_get_peb and then resolve a module by its’ x65599 hash:
// Structure definitions omitted for clarity
uintptr_t riscvm_resolve_dll(uint32_t module_hash)
{
static PEB* peb = 0;
if (!peb)
{
peb = (PEB*)riscvm_get_peb();
}
LIST_ENTRY* begin = &peb->Ldr->InLoadOrderModuleList;
for (LIST_ENTRY* itr = begin->Flink; itr != begin; itr = itr->Flink)
{
LDR_DATA_TABLE_ENTRY* entry = CONTAINING_RECORD(itr, LDR_DATA_TABLE_ENTRY, InLoadOrderLinks);
if (entry->BaseNameHashValue == module_hash)
{
return (uintptr_t)entry->DllBase;
}
}
return 0;
}
Once we’ve obtained the base of the module we’re interested in, we can resolve the import by walking the export table:
uintptr_t riscvm_resolve_import(uintptr_t image, uint32_t export_hash)
{
IMAGE_DOS_HEADER* dos_header = (IMAGE_DOS_HEADER*)image;
IMAGE_NT_HEADERS* nt_headers = (IMAGE_NT_HEADERS*)(image + dos_header->e_lfanew);
uint32_t export_dir_size = nt_headers->OptionalHeader.DataDirectory[0].Size;
IMAGE_EXPORT_DIRECTORY* export_dir =
(IMAGE_EXPORT_DIRECTORY*)(image + nt_headers->OptionalHeader.DataDirectory[0].VirtualAddress);
uint32_t* names = (uint32_t*)(image + export_dir->AddressOfNames);
uint32_t* funcs = (uint32_t*)(image + export_dir->AddressOfFunctions);
uint16_t* ords = (uint16_t*)(image + export_dir->AddressOfNameOrdinals);
for (uint32_t i = 0; i < export_dir->NumberOfNames; ++i)
{
char* name = (char*)(image + names[i]);
uintptr_t func = (uintptr_t)(image + funcs[ords[i]]);
// Ignore forwarded exports
if (func >= (uintptr_t)export_dir && func < (uintptr_t)export_dir + export_dir_size)
continue;
uint32_t hash = hash_x65599(name, true);
if (hash == export_hash)
{
return func;
}
}
return 0;
}
Now we can call MessageBoxA from RISC-V with the following code:
// NOTE: We cannot use Windows.h here
#include <stdint.h>
int main()
{
// Resolve LoadLibraryA
auto kernel32_dll = riscvm_resolve_dll(hash_x65599("kernel32.dll", false))
auto LoadLibraryA = riscvm_resolve_import(kernel32_dll, hash_x65599("LoadLibraryA", true))
// Load user32.dll
uint64_t args[13];
args[0] = (uint64_t)"user32.dll";
auto user32_dll = riscvm_host_call(LoadLibraryA, args);
// Resolve MessageBoxA
auto MessageBoxA = riscvm_resolve_import(user32_dll, hash_x65599("MessageBoxA", true));
// Show a message to the user
args[0] = 0; // hwnd
args[1] = (uint64_t)"Hello from RISC-V!"; // msg
args[2] = (uint64_t)"riscvm"; // title
args[3] = 0; // flags
riscvm_host_call(MessageBoxA, args);
}
With some templates/macros/constexpr tricks we can probably get this down to something more readable, but fundamentally this code will always stay annoying to write. Even if calling imports were a one-liner, we would still have to deal with the fact that we cannot use Windows.h (or any of the Microsoft headers for that matter). The reason for this is that we are cross-compiling with Clang. Even if we were to set up the include paths correctly, it would still be a major pain to get everything to compile correctly. That being said, our VM works! A major advantage of RISC-V is that, since the instruction set is simple, once the fundamentals work, we can be confident that features built on top of this will execute as expected.
Whole Program LLVM
Usually, when discussing LLVM, the compilation process is running on Linux/macOS. In this section, we will describe a pipeline that can actually be used on Windows, without making modifications to your toolchain. This is useful if you would like to analyze/fuzz/obfuscate Windows applications, which might only compile an MSVC-compatible compiler: clang-cl.
Link-time optimization (LTO)
Without LTO, the object files produced by Clang are native COFF/ELF/Mach-O files. Every file is optimized and compiled independently. The linker loads these objects and merges them together into the final executable.
When enabling LTO, the object files are instead LLVM Bitcode (.bc) files. This allows the linker to merge all the LLVM IR together and perform (more comprehensive) whole-program optimizations. After the LLVM IR has been optimized, the native code is generated and the final executable produced. The diagram below comes from the great Link-time optimisation (LTO) post by Ryan Stinnet:

Compiler wrappers
Unfortunately, it can be quite annoying to write an executable that can replace the compiler. It is quite simple when dealing with a few object files, but with bigger projects it gets quite tricky (especially when CMake is involved). Existing projects are WLLVM and gllvm, but they do not work nicely on Windows. When using CMake, you can use the CMAKE_<LANG>_COMPILER_LAUNCHER variables and intercept the compilation pipeline that way, but that is also tricky to deal with.
On Windows, things are more complex than on Linux. This is because Clang uses a different program to link the final executable and correctly intercepting this process can become quite challenging.
Embedding bitcode
To achieve our goal of post-processing the bitcode of the whole program, we need to enable bitcode embedding. The first flag we need is -flto, which enables LTO. The second flag is -lto-embed-bitcode, which isn’t documented very well. When using clang-cl, you also need a special incantation to enable it:
set(EMBED_TYPE "post-merge-pre-opt") # post-merge-pre-opt/optimized
if(NOT CMAKE_CXX_COMPILER_ID MATCHES "Clang")
if(WIN32)
message(FATAL_ERROR "clang-cl is required, use -T ClangCL --fresh")
else()
message(FATAL_ERROR "clang compiler is required")
endif()
elseif(CMAKE_CXX_COMPILER_FRONTEND_VARIANT MATCHES "^MSVC$")
# clang-cl
add_compile_options(-flto)
add_link_options(/mllvm:-lto-embed-bitcode=${EMBED_TYPE})
elseif(WIN32)
# clang (Windows)
add_compile_options(-fuse-ld=lld-link -flto)
add_link_options(-Wl,/mllvm:-lto-embed-bitcode=${EMBED_TYPE})
else()
# clang (Linux)
add_compile_options(-fuse-ld=lld -flto)
add_link_options(-Wl,-lto-embed-bitcode=${EMBED_TYPE})
endif()
The -lto-embed-bitcode flag creates an additional .llvmbc section in the final executable that contains the bitcode. It offers three settings:
-lto-embed-bitcode=<value> - Embed LLVM bitcode in object files produced by LTO
=none - Do not embed
=optimized - Embed after all optimization passes
=post-merge-pre-opt - Embed post merge, but before optimizations
Once the bitcode is embedded within the output binary, it can be extracted using llvm-objcopy and disassembled with llvm-dis. This is normally done as the follows:
llvm-objcopy --dump-section=.llvmbc=program.bc program
llvm-dis program.bc > program.ll
Unfortunately, we discovered a bug/oversight in LLD on Windows. The section is extracted without errors, but llvm-dis fails to load the bitcode. The reason for this is that Windows executables have a FileAlignment attribute, leading to additional padding with zeroes. To get valid bitcode, you need to remove some of these trailing zeroes:
import argparse
import sys
import pefile
def main():
# Parse the arguments
parser = argparse.ArgumentParser()
parser.add_argument("executable", help="Executable with embedded .llvmbc section")
parser.add_argument("--output", "-o", help="Output file name", required=True)
args = parser.parse_args()
executable: str = args.executable
output: str = args.output
# Find the .llvmbc section
pe = pefile.PE(executable)
llvmbc = None
for section in pe.sections:
if section.Name.decode("utf-8").strip("\x00") == ".llvmbc":
llvmbc = section
break
if llvmbc is None:
print("No .llvmbc section found")
sys.exit(1)
# Recover the bitcode and write it to a file
with open(output, "wb") as f:
data = bytearray(llvmbc.get_data())
# Truncate all trailing null bytes
while data[-1] == 0:
data.pop()
# Recover alignment to 4
while len(data) % 4 != 0:
data.append(0)
# Add a block end marker
for _ in range(4):
data.append(0)
f.write(data)
if __name__ == "__main__":
main()
In our testing, this doesn’t have any issues, but there might be cases where this heuristic does not work properly. In that case, a potential solution could be to brute force the amount of trailing zeroes, until the bitcode parses without errors.
Applications
Now that we have access to our program’s bitcode, several applications become feasible:
- Write an analyzer to identify potentially interesting locations within the program.
- Instrument the bitcode and then re-link the executable, which is particularly useful for code coverage while fuzzing.
- Obfuscate the bitcode before re-linking the executable, enhancing security.
- IR retargeting, where the bitcode compiled for one architecture can be used on another.
Relinking the executable
The bitcode itself unfortunately does not contain enough information to re-link the executable (although this is something we would like to implement upstream). We could either manually attempt to reconstruct the linker command line (with tools like Process Monitor), or use LLVM plugin support. Plugin support is not really functional on Windows (although there is some indication that Sony is using it for their PS4/PS5 toolchain), but we can still load an arbitrary DLL using the -load command line flag. Once we loaded our DLL, we can hijack the executable command line and process the flags to generate a script for re-linking the program after our modifications are done.
Retargeting LLVM IR
Ideally, we would want to write code like this and magically get it to run in our VM:
#include <Windows.h>
int main()
{
MessageBoxA(0, "Hello from RISC-V!", "riscvm", 0);
}
Luckily this is entirely possible, it just requires writing a (fairly) simple tool to perform transformations on the Bitcode of this program (built using clang-cl). In the coming sections, we will describe how we managed to do this using Microsoft Visual Studio’s official LLVM integration (i.e. without having to use a custom fork of clang-cl).
The LLVM IR of the example above looks roughly like this (it has been cleaned up slightly for readability):
source_filename = "hello.c"
target datalayout = "e-m:w-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-pc-windows-msvc19.38.33133"
@message = dso_local global [19 x i8] c"Hello from RISC-V!\00", align 16
@title = dso_local global [7 x i8] c"riscvm\00", align 1
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @main() #0 {
%1 = call i32 @MessageBoxA(ptr noundef null, ptr noundef @message, ptr noundef @title, i32 noundef 0)
ret i32 0
}
declare dllimport i32 @MessageBoxA(ptr noundef, ptr noundef, ptr noundef, i32 noundef) #1
attributes #0 = { noinline nounwind optnone uwtable "min-legal-vector-width"="0" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" }
attributes #1 = { "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" }
!llvm.linker.options = !{!0, !0}
!llvm.module.flags = !{!1, !2, !3}
!llvm.ident = !{!4}
!0 = !{!"/DEFAULTLIB:uuid.lib"}
!1 = !{i32 1, !"wchar_size", i32 2}
!2 = !{i32 8, !"PIC Level", i32 2}
!3 = !{i32 7, !"uwtable", i32 2}
!4 = !{!"clang version 16.0.5"}
To retarget this code to RISC-V, we need to do the following:
- Collect all the functions with a
dllimportstorage class. - Generate a
riscvm_importsfunction that resolves all the function addresses of the imports. - Replace the
dllimportfunctions with stubs that useriscvm_host_callto call the import. - Change the target triple to
riscv64-unknown-unknownand adjust the data layout. - Compile the retargeted bitcode and link it together with
crt0to create the final payload.
Adjusting the metadata
After loading the LLVM IR Module, the first step is to change the DataLayout and the TargetTriple to be what the RISC-V backend expects:
module.setDataLayout("e-m:e-p:64:64-i64:64-i128:128-n32:64-S128");
module.setTargetTriple("riscv64-unknown-unknown");
module.setSourceFileName("transpiled.bc");
The next step is to collect all the dllimport functions for later processing. Additionally, a bunch of x86-specific function attributes are removed from every function:
std::vector<Function*> importedFunctions;
for (Function& function : module.functions())
{
// Remove x86-specific function attributes
function.removeFnAttr("target-cpu");
function.removeFnAttr("target-features");
function.removeFnAttr("tune-cpu");
function.removeFnAttr("stack-protector-buffer-size");
// Collect imported functions
if (function.hasDLLImportStorageClass() && !function.getName().startswith("riscvm_"))
{
importedFunctions.push_back(&function);
}
function.setDLLStorageClass(GlobalValue::DefaultStorageClass);
Finally, we have to remove the llvm.linker.options metadata to make sure we can pass the IR to llc or clang without errors.
Import map
The LLVM IR only has the dllimport storage class to inform us that a function is imported. Unfortunately, it does not provide us with the DLL the function comes from. Because this information is only available at link-time (in files like user32.lib), we decided to implement an extra -importmap argument.
The extract-bc script that extracts the .llvmbc section now also has to extract the imported functions and what DLL they come from:
with open(importmap, "wb") as f:
for desc in pe.DIRECTORY_ENTRY_IMPORT:
dll = desc.dll.decode("utf-8")
for imp in desc.imports:
name = imp.name.decode("utf-8")
f.write(f"{name}:{dll}\n".encode("utf-8"))
Currently, imports by ordinal and API sets are not supported, but we can easily make sure those do not occur when building our code.
Creating the import stubs
For every dllimport function, we need to add some IR to riscvm_imports to resolve the address. Additionally, we have to create a stub that forwards the function arguments to riscvm_host_call. This is the generated LLVM IR for the MessageBoxA stub:
; Global variable to hold the resolved import address
@import_MessageBoxA = private global ptr null
define i32 @MessageBoxA(ptr noundef %0, ptr noundef %1, ptr noundef %2, i32 noundef %3) local_unnamed_addr #1 {
entry:
%args = alloca ptr, i32 13, align 8
%arg3_zext = zext i32 %3 to i64
%arg3_cast = inttoptr i64 %arg3_zext to ptr
%import_address = load ptr, ptr @import_MessageBoxA, align 8
%arg0_ptr = getelementptr ptr, ptr %args, i32 0
store ptr %0, ptr %arg0_ptr, align 8
%arg1_ptr = getelementptr ptr, ptr %args, i32 1
store ptr %1, ptr %arg1_ptr, align 8
%arg2_ptr = getelementptr ptr, ptr %args, i32 2
store ptr %2, ptr %arg2_ptr, align 8
%arg3_ptr = getelementptr ptr, ptr %args, i32 3
store ptr %arg3_cast, ptr %arg3_ptr, align 8
%return = call ptr @riscvm_host_call(ptr %import_address, ptr %args)
%return_cast = ptrtoint ptr %return to i64
%return_trunc = trunc i64 %return_cast to i32
ret i32 %return_trunc
}
The uint64_t args[13] array is allocated on the stack using the alloca instruction and every function argument is stored in there (after being zero-extended). The GlobalVariable named import_MessageBoxA is read and finally riscvm_host_call is executed to call the import on the host side. The return value is truncated as appropriate and returned from the stub.
The LLVM IR for the generated riscvm_imports function looks like this:
; Global string for LoadLibraryA
@str_USER32.dll = private constant [11 x i8] c"USER32.dll\00"
define void @riscvm_imports() {
entry:
%args = alloca ptr, i32 13, align 8
%kernel32.dll_base = call ptr @riscvm_resolve_dll(i32 1399641682)
%import_LoadLibraryA = call ptr @riscvm_resolve_import(ptr %kernel32.dll_base, i32 -550781972)
%arg0_ptr = getelementptr ptr, ptr %args, i32 0
store ptr @str_USER32.dll, ptr %arg0_ptr, align 8
%USER32.dll_base = call ptr @riscvm_host_call(ptr %import_LoadLibraryA, ptr %args)
%import_MessageBoxA = call ptr @riscvm_resolve_import(ptr %USER32.dll_base, i32 -50902915)
store ptr %import_MessageBoxA, ptr @import_MessageBoxA, align 8
ret void
}
The resolving itself uses the riscvm_resolve_dll and riscvm_resolve_import functions we discussed in a previous section. The final detail is that user32.dll is not loaded into every process, so we need to manually call LoadLibraryA to resolve it.
Instead of resolving the DLL and import hashes at runtime, they are resolved by the transpiler at compile-time, which makes things a bit more annoying to analyze for an attacker.
Trade-offs
While the retargeting approach works well for simple C++ code that makes use of the Windows API, it currently does not work properly when the C/C++ standard library is used. Getting this to work properly will be difficult, but things like std::vector can be made to work with some tricks. The limitations are conceptually quite similar to driver development and we believe this is a big improvement over manually recreating types and manual wrappers with riscvm_host_call.
An unexplored potential area for bugs is the unverified change to the DataLayout of the LLVM module. In our tests, we did not observe any differences in structure layouts between rv64 and x64 code, but most likely there are some nasty edge cases that would need to be properly handled.
If the code written is mainly cross-platform, portable C++ with heavy use of the STL, an alternative design could be to compile most of it with a regular C++ cross-compiler and use the retargeting only for small Windows-specific parts.
One of the biggest advantages of retargeting a (mostly) regular Windows C++ program is that the payload can be fully developed and tested on Windows itself. Debugging is much more difficult once the code becomes RISC-V and our approach fully decouples the development of the payload from the VM itself.
CRT0
The final missing piece of the crt0 component is the _start function that glues everything together:
static void exit(int exit_code);
static void riscvm_relocs();
void riscvm_imports() __attribute__((weak));
static void riscvm_init_arrays();
extern int __attribute((noinline)) main();
// NOTE: This function has to be first in the file
void _start()
{
riscvm_relocs();
riscvm_imports();
riscvm_init_arrays();
exit(main());
asm volatile("ebreak");
}
void riscvm_imports()
{
// Left empty on purpose
}
The riscvm_imports function is defined as a weak symbol. This means the implementation provided in crt0.c can be overwritten by linking to a stronger symbol with the same name. If we generate a riscvm_imports function in our retargeted bitcode, that implementation will be used and we can be certain we execute before main!
Example payload project
Now that all the necessary tooling has been described, we can put everything together in a real project! In the repository, this is all done in the payload folder. To make things easy, this is a simple cmkr project with a template to enable the retargeting scripts:
# Reference: https://build-cpp.github.io/cmkr/cmake-toml
[cmake]
version = "3.19"
cmkr-include = "cmake/cmkr.cmake"
[project]
name = "payload"
languages = ["CXX"]
cmake-before = "set(CMAKE_CONFIGURATION_TYPES Debug Release)"
include-after = ["cmake/riscvm.cmake"]
msvc-runtime = "static"
[fetch-content.phnt]
url = "https://github.com/mrexodia/phnt-single-header/releases/download/v1.2-4d1b102f/phnt.zip"
[template.riscvm]
type = "executable"
add-function = "add_riscvm_executable"
[target.payload]
type = "riscvm"
sources = [
"src/main.cpp",
"crt/minicrt.c",
"crt/minicrt.cpp",
]
include-directories = [
"include",
]
link-libraries = [
"riscvm-crt0",
"phnt::phnt",
]
compile-features = ["cxx_std_17"]
msvc.link-options = [
"/INCREMENTAL:NO",
"/DEBUG",
]
In this case, the add_executable function has been replaced with an equivalent add_riscvm_executable that creates an additional payload.bin file that can be consumed by the riscvm interpreter. The only thing we have to make sure of is to enable clang-cl when configuring the project:
cmake -B build -T ClangCL
After this, you can open build\payload.sln in Visual Studio and develop there as usual. The custom cmake/riscvm.cmake script does the following:
- Enable LTO
- Add the
-lto-embed-bitcodelinker flag - Locale
clang.exe,ld.lld.exeandllvm-objcopy.exe - Compile
crt0.cfor theriscv64architecture - Create a Python virtual environment with the necessary dependencies
The add_riscvm_executable adds a custom target that processes the regular output executable and executes the retargeter and relevant Python scripts to produce the riscvm artifacts:
function(add_riscvm_executable tgt)
add_executable(${tgt} ${ARGN})
if(MSVC)
target_compile_definitions(${tgt} PRIVATE _NO_CRT_STDIO_INLINE)
target_compile_options(${tgt} PRIVATE /GS- /Zc:threadSafeInit-)
endif()
set(BC_BASE "$<TARGET_FILE_DIR:${tgt}>/$<TARGET_FILE_BASE_NAME:${tgt}>")
add_custom_command(TARGET ${tgt}
POST_BUILD
USES_TERMINAL
COMMENT "Extracting and transpiling bitcode..."
COMMAND "${Python3_EXECUTABLE}" "${RISCVM_DIR}/extract-bc.py" "$<TARGET_FILE:${tgt}>" -o "${BC_BASE}.bc" --importmap "${BC_BASE}.imports"
COMMAND "${TRANSPILER}" -input "${BC_BASE}.bc" -importmap "${BC_BASE}.imports" -output "${BC_BASE}.rv64.bc"
COMMAND "${CLANG_EXECUTABLE}" ${RV64_FLAGS} -c "${BC_BASE}.rv64.bc" -o "${BC_BASE}.rv64.o"
COMMAND "${LLD_EXECUTABLE}" -o "${BC_BASE}.elf" --oformat=elf -emit-relocs -T "${RISCVM_DIR}/lib/linker.ld" "--Map=${BC_BASE}.map" "${CRT0_OBJ}" "${BC_BASE}.rv64.o"
COMMAND "${OBJCOPY_EXECUTABLE}" -O binary "${BC_BASE}.elf" "${BC_BASE}.pre.bin"
COMMAND "${Python3_EXECUTABLE}" "${RISCVM_DIR}/relocs.py" "${BC_BASE}.elf" --binary "${BC_BASE}.pre.bin" --output "${BC_BASE}.bin"
COMMAND "${Python3_EXECUTABLE}" "${RISCVM_DIR}/encrypt.py" --encrypt --shuffle --map "${BC_BASE}.map" --shuffle-map "${RISCVM_DIR}/shuffled_opcodes.json" --opcodes-map "${RISCVM_DIR}/opcodes.json" --output "${BC_BASE}.enc.bin" "${BC_BASE}.bin"
VERBATIM
)
endfunction()
While all of this is quite complex, we did our best to make it as transparent to the end-user as possible. After enabling Visual Studio’s LLVM support in the installer, you can start developing VM payloads in a few minutes. You can get a precompiled transpiler binary from the releases.
Debugging in riscvm
When debugging the payload, it is easiest to load payload.elf in Ghidra to see the instructions. Additionally, the debug builds of the riscvm executable have a --trace flag to enable instruction tracing. The execution of main in the MessageBoxA example looks something like this (labels added manually for clarity):
main:
0x000000014000d3a4: addi sp, sp, -0x10 = 0x14002cfd0
0x000000014000d3a8: sd ra, 0x8(sp) = 0x14000d018
0x000000014000d3ac: auipc a0, 0x0 = 0x14000d4e4
0x000000014000d3b0: addi a1, a0, 0xd6 = 0x14000d482
0x000000014000d3b4: auipc a0, 0x0 = 0x14000d3ac
0x000000014000d3b8: addi a2, a0, 0xc7 = 0x14000d47b
0x000000014000d3bc: addi a0, zero, 0x0 = 0x0
0x000000014000d3c0: addi a3, zero, 0x0 = 0x0
0x000000014000d3c4: jal ra, 0x14 -> 0x14000d3d8
MessageBoxA:
0x000000014000d3d8: addi sp, sp, -0x70 = 0x14002cf60
0x000000014000d3dc: sd ra, 0x68(sp) = 0x14000d3c8
0x000000014000d3e0: slli a3, a3, 0x0 = 0x0
0x000000014000d3e4: srli a4, a3, 0x0 = 0x0
0x000000014000d3e8: auipc a3, 0x0 = 0x0
0x000000014000d3ec: ld a3, 0x108(a3=>0x14000d4f0) = 0x7ffb3c23a000
0x000000014000d3f0: sd a0, 0x0(sp) = 0x0
0x000000014000d3f4: sd a1, 0x8(sp) = 0x14000d482
0x000000014000d3f8: sd a2, 0x10(sp) = 0x14000d47b
0x000000014000d3fc: sd a4, 0x18(sp) = 0x0
0x000000014000d400: addi a1, sp, 0x0 = 0x14002cf60
0x000000014000d404: addi a0, a3, 0x0 = 0x7ffb3c23a000
0x000000014000d408: jal ra, -0x3cc -> 0x14000d03c
riscvm_host_call:
0x000000014000d03c: lui a2, 0x5 = 0x14000d47b
0x000000014000d040: addiw a7, a2, -0x1e0 = 0x4e20
0x000000014000d044: ecall 0x4e20
0x000000014000d048: ret (0x14000d40c)
0x000000014000d40c: ld ra, 0x68(sp=>0x14002cfc8) = 0x14000d3c8
0x000000014000d410: addi sp, sp, 0x70 = 0x14002cfd0
0x000000014000d414: ret (0x14000d3c8)
0x000000014000d3c8: addi a0, zero, 0x0 = 0x0
0x000000014000d3cc: ld ra, 0x8(sp=>0x14002cfd8) = 0x14000d018
0x000000014000d3d0: addi sp, sp, 0x10 = 0x14002cfe0
0x000000014000d3d4: ret (0x14000d018)
0x000000014000d018: jal ra, 0x14 -> 0x14000d02c
exit:
0x000000014000d02c: lui a1, 0x2 = 0x14002cf60
0x000000014000d030: addiw a7, a1, 0x710 = 0x2710
0x000000014000d034: ecall 0x2710
The tracing also uses the enums for the opcodes, so it works with shuffled and encrypted payloads as well.
Outro
Hopefully this article has been an interesting read for you. We tried to walk you through the process in the same order we developed it in, but you can always refer to the riscy-business GitHub repository and try things out for yourself if you got confused along the way. If you have any ideas for improvements, or would like to discuss, you are always welcome in our Discord server!
We would like to thank the following people for proofreading and discussing the design and implementation with us (alphabetical order):
Additionally, we highly appreciate the open source projects that we built this project on! If you use this project, consider giving back your improvements to the community as well.
Merry Christmas!